From Data Chaos to Strategic Clarity
In today's data-rich environment, the challenge isn't finding information—it's transforming vast, disparate data sources into meaningful intelligence that drives decisions. Our custom data pipeline solutions are engineered to handle the complexity of modern data ecosystems.
We build robust, scalable infrastructure that automatically collects, cleanses, processes, and analyzes data from hundreds of sources simultaneously, delivering real-time intelligence that keeps you ahead of the curve.
Key Benefits
- Real-time Processing: Stream processing capabilities for immediate insights and alerts
- Scalable Architecture: Handle millions of data points without performance degradation
- Data Quality Assurance: Built-in validation and cleansing ensure accuracy and reliability
- Custom Integration: Seamlessly connect with your existing systems and workflows
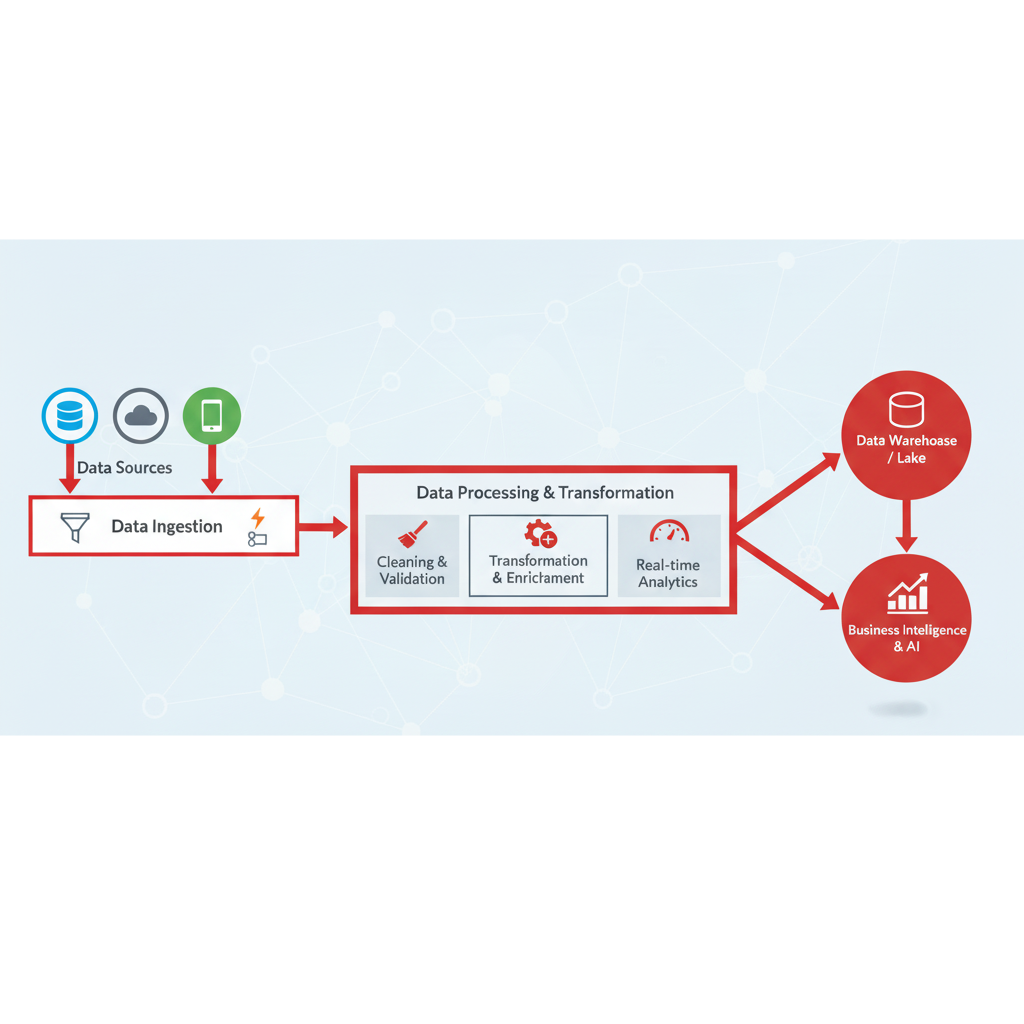
Pipeline Capabilities
Comprehensive data processing solutions tailored to your intelligence needs
Multi-Source Ingestion
Connect to APIs, databases, social media, news feeds, government data, and proprietary sources through unified interfaces with intelligent rate limiting and error handling.
Real-time Stream Processing
Process high-velocity data streams in real-time with advanced filtering, transformation, and enrichment capabilities for immediate actionable insights.
Automated Data Cleansing
Machine learning algorithms automatically detect and correct data quality issues, remove duplicates, and standardize formats across sources.
Intelligent Monitoring
Comprehensive monitoring and alerting systems track pipeline health, data quality metrics, and system performance with automated recovery protocols.
Data Source Categories
Social Media & Digital
- Twitter, Facebook, LinkedIn APIs
- News aggregation services
- Blog and forum monitoring
- Video platform analytics
Government & Public
- Open data portals
- Regulatory filings
- Census and demographic data
- Legislative tracking systems
Financial & Market
- Market data feeds
- Economic indicators
- Corporate earnings reports
- Trading volume analytics
Research & Academic
- Scientific publication databases
- Patent filing systems
- Research institution reports
- Academic collaboration networks
Success Stories
Real-world implementations of our data pipeline solutions
GDELT News Scraping Pipeline
Customer IntelligenceEnterprise-scale news article extraction system featuring asynchronous processing of 15 000,000+ URLs with robust checkpoint recovery, batch processing architecture, and multi-tier error handling. Implemented comprehensive deduplication algorithms, real-time progress tracking, and timestamped output organization, enabling reliable large-scale news data collection with automatic interruption recovery and configurable batch sizes for optimal resource management.
Media Cloud Data Collection Pipeline
Data CollectionAutomated CSV extraction system with session management for authenticated data collection, dynamic URL handling with intelligent retry mechanisms, and structured data validation ensuring integrity throughout collection. Implemented checkpoint-enabled processing for large datasets, scalable concurrent operations, and configurable rate limiting, delivering reliable automated media data harvesting with robust error handling and progress persistence
Web Data Processing Framework
Market IntelligenceModular scraping architecture with configurable rate limiting, multi-format output support, error categorization and comprehensive logging for pipeline health monitoring. Features fault-tolerant design with automatic recovery, performance optimization through asynchronous processing, scalable concurrent operations with adjustable worker pools, and extensible modular architecture enabling easy customization for diverse web data collection requirements.
Our Implementation Process
Requirements Analysis
Deep dive into your data landscape, identifying sources, defining objectives, and mapping existing infrastructure to design the optimal pipeline architecture.
1-2 weeksArchitecture Design
Create detailed technical specifications, select appropriate technologies, and design scalable, fault-tolerant pipeline architecture with security best practices.
2-3 weeksDevelopment & Testing
Build and rigorously test pipeline components, implement data quality checks, and conduct performance optimization under various load conditions.
4-6 weeksDeployment & Monitoring
Deploy to production with comprehensive monitoring, provide team training, and establish ongoing support and maintenance protocols.
1-2 weeksReady to Transform Your Data Infrastructure?
Let's design a custom data pipeline solution that turns your information challenges into strategic advantages.